English Italiano
Advanced Search
The Advanced Search provides a menu-based interface that allows users to search for complex text patterns. It permits searches for defined sequences of words, specified by inflected or base form as well as by word class (part of speech, pos).
Furthermore, it allows users to search for dependency relations, such as the subject of a passive sentence.
A detailed search menu provides different options for personalizing displayed results.
Searching for inflected forms, lemmas and parts of speech (POS)
In the Advanced Search mode, the user can choose whether to specify the search word on the level of word form (any inflected word form, e.g. "vado"), lemma (any base form, e.g. "andare") or part of speech (any word class, e.g. "verb"). The selected form has to be entered in the corresponding field ("form", "lemma", "POS"), and several fields can be specified jointly. Screenshot below shows a search example for the word form "gelato" occurring as an "adjective".
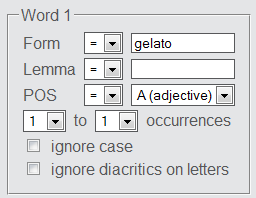
The option "ignore case" disregards differences between identical words written in upper or lower case.
Searching for Italiano will return sentences containing the word "Italiano", "italiano" and "ITALIANO".
The option "ignore diacritics" disregards accents and other word diacritics.
Searching for papà will return sentences containing the word "papa" or "papà".
Search with regular expressions
The search fields "form" and "lemma" allow for entering regular expressions to define a search pattern. Regular expressions allow users to search for word classes by using placeholders ("." stands for any letter; * stands for 0 to n occurrences of the preceding letter; + stands for 1 to n occurrences of the preceding letter) or groups of letters or substrings ([aei] stands for any of the three letters; (erò|erai|erà|eremo|erete|eranno) stands for any of these verb endings in future tense). To learn more about the use of regular expressions, look up the CQP tutorial here.
Some examples:
- Searching for c.ntare in the field "form" will return sentences containing the word forms "cantare" or "cintare" or "contare".
- Searching for dit*o will return sentences containing the word form "dio", "ditto" or "dito".
- Searching for per.+ will return sentences containing word forms starting with the string "per", but not the form "per" as a whole word.
- Searching for buon[oaei] will return sentences containing "buono", "buona", "buoni" o "buone".
- Searching for trov(erò|erai|erà|eremo|erete|eranno) will return any of the six forms of the simple future of the verb "trovare".
- Searching for .* will return ANY word.
Searching for sequences of words
The interface provides three word positions (Word 1,2,3) plus two slots for specifying distances between words (# words, i.e. the number of intervening words). The query in the screenshot below returns sentences that contain a sequence of words starting with any inflected form of the lemma "mettere" followed by any word, followed by the word form "insieme" followed by 2 or more words, followed by a common noun.
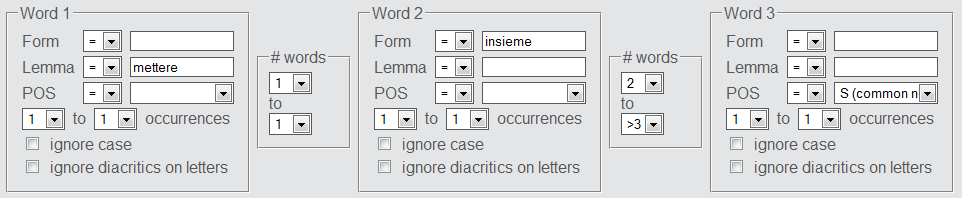
Examples for retrieved sequences include:
- "messe tutte insieme in una sola mano…"
- "Messi tutti insieme arriverebbero invece ad oltre 36.682 esemplari…"
- "Mettendo queste insieme a 60 bombe…"
Searching for dependency relations
The corpus can be searched by dependency relations. The relation type is selected through "further search options" by referencing words (or lemmas or POS) specified in Word 1,2,3 positions.
The screenshot below gives a search example for sentences containing the word form "buona" (Word 1) at a distance of one word from any common noun, where "buona" is in a "modifier" relation to a common noun (Word 2).
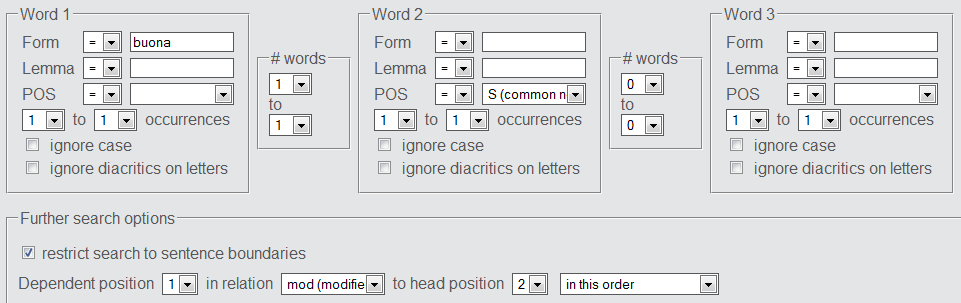
Examples for returned sentences include:
- "Malgrado una buona prima parte di stagione, la squadra…"
- "…faceva finta di volere lasciare la moglie solo per tenere buona la ragazza…"
By selecting "in this or inverse order" from the drop-box, yet other examples are returned with "buona" is following the common noun.
Examples include:
- "Una qualità molto buona significa inoltre…"
- "…nonostante fosse un' idea teoricamente buona per raggiungere…"
The screenshot below shows how to search for all occurrences of the lemma "mangiare" together with its direct object. The results are returned with "mangiare" and "obj" occurring in any order, as enforced by selecting the option "in this or inverse order". Note that Word 2 is left unspecified by entering the regular expression ".*" into the box for the word form.
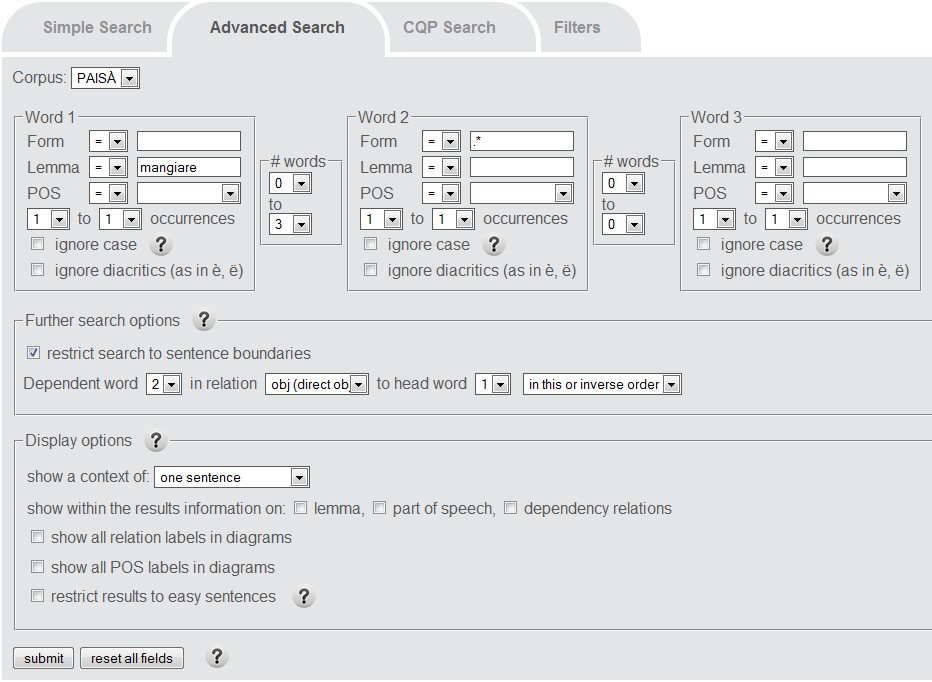
Example hits include:
- "mangia prevalentemente nocciole"
- "mangia la frutta"
- "lo mangia"
- "cosa mangiano"
Below (screenshot) you can find yet another example of a complex search with a condition on the dependency relation. The search pattern is intended to retrieve any occurrence of two nouns with one intervening word, where both nouns start in a vowel and stand in the dependency relation "conjunct linked by con" (conj).
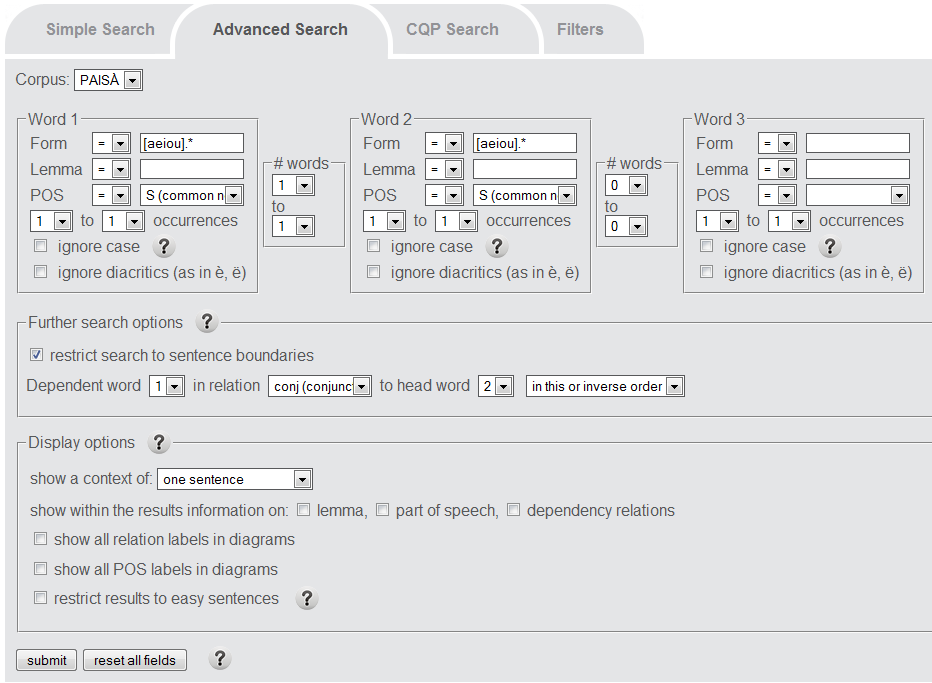
Example hits include:
- "esercizi ed esempi"
- "interfaccia e implementazione"
- "entrate e uscite"
Display of results
Search results are displayed as Key Word In Context lines or as dependency diagrams. The user can choose the width of the context to display, and which annotations to include.
From a drop-down menu the user can choose to view a full sentence, or 5, 10, or 15 words of context on each side of the keyword.
Lemma and part of speech information can be selected for display. Lemma information is placed after each word form. It is presented in parentheses and lighter colour. The lemma is omitted if it is identical to the word form. Part of speech information is attached to the word as subscript.
If the user chooses to view dependency information, the displayed context is by default one single sentence. 5 hits are shown on each page. Part of speech labels are displayed below the diagram.
By clicking on any of the icons on the right of the KWIC line, additional information can be accessed:
-
 shows the entire sentence. To revert
to the KWIC view the
shows the entire sentence. To revert
to the KWIC view the  is used.
is used.
-
 shows the dependency diagram with
the sentence. To learn how to interact with the dependency diagram click
here.
shows the dependency diagram with
the sentence. To learn how to interact with the dependency diagram click
here.
-
 opens the full text document in a
new window/tab.
opens the full text document in a
new window/tab.
-
 indicates the URL which the text was
taken from.
indicates the URL which the text was
taken from.
You need more help? See here for an overview of our help pages.